

One of the downfalls of Azure Data Explorer is that it lacks built-in functionality to backup & restore databases. At least not in the way we know it in SQL server. A solution that might solve the problem is using on-demand data recovery. This solution is proposed by Microsoft as one of the options for business continuity.
The concept (see the picture below) of on-demand data recovery is to continuous export the data from Azure Data Explorer to an Azure Storage Account and, in case of a disaster, start or create a new cluster. This second cluster will read the data from the external table.
But we can also use this solution as a backup & restore mechanism.

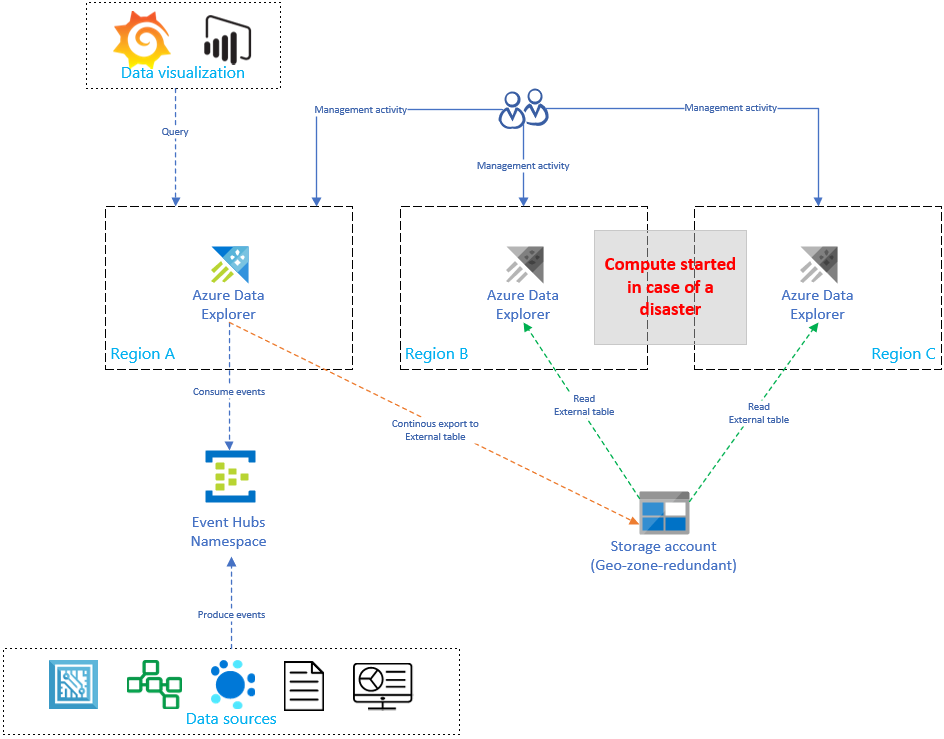
In this blog, we will check how this solution works and how it performs with large datasets.
Prerequisites
- An Azure Data Explorer cluster, with a database
- An Azure Storage account
In this blog we restore the data to a second Azure Data Explorer cluster. This is optional, it is also possible to restore the data in the same cluster.
Preparations
Before we start with the backup & restore, let’s create a simple table to test with:
.create table MyTestTable (['id']: int, name: string, value: real, timestamp: datetime)
I also added some data:
.ingest inline into table MyTestTable
[1,test,2,2024-01-01]
[1,test,4,2024-01-02]
[2,test,1,2024-01-01]
[2,test,2,2024-01-02]
[2,test,4,2024-01-03]
Backup
At first, we need to create the backup. In Azure Data Explorer this is done by 3 steps:
- Create an external table
- Create a continuous data export
- Export historical data (optional)
External table
I started to create an external table called ExternalTable_MyTestTable. This external table is partitioned by the timestamp, and therefor create a folder for each date within the container. In this example, I will export the data as parquet files, but there are several other possibilities.
.create-or-alter external table ExternalTable_MyTestTable (['id']: int, name: string, value: real, timestamp: datetime)
kind=storage
partition by ( Date:datetime = startofday(timestamp))
pathformat=(datetime_pattern("yyyyMMdd", Date))
dataformat=parquet
(
h@'https://<storagename>.blob.core.windows.net/<containername>;<secret>'
)
To check the content of the external table, execute:
//See data of external table
external_table("ExternalTable_MyTestTable")
This will return an empty table because we didn’t ingest any data yet.
Continuous export
Next step, is to enable continuous export. The script below will create a continuous export called Export_MyTestTable with table MyTestTable as source. The data will be exported every minute, this is the lowest granularity to export data.
//create continuous export .create-or-alter continuous-export Export_MyTestTable over (MyTestTable) to table ExternalTable_MyTestTable with (intervalBetweenRuns=1m) <| MyTestTable
To view all continuous exports, execute the script below:
.show continuous-exports
The result:


Continuous export is now enabled and will export any records that would be ingested to the table. Later on in this article, I will demonstrate this.
If you have multiple tables, you need to enable continuous export for each table, there is not an option to enable continuous export for all tables in the database. So if you want to backup the whole database, this means a lot more work.
Export historical data
But first we need to export the data that was already in the table before enabling the continuous export. Continuous export starts exporting data only from the point of its creation, records ingested before that time should be exported manually.
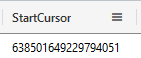
Before we can start exporting the historical data, we should retrieve the StartCursor. The StartCursor indicates the last value that has been exported. So we want to manually export only the records before that point.
.show continuous-export MyExport | project StartCursor

Use the retrieved StartCursor in the query to export the data to the Storage Account. For this, we use the external table we created earlier.
//export historical data
.export async to table ExternalTable_MyTestTable
<| MyTestTable | where cursor_before_or_at("<StartCursor>")

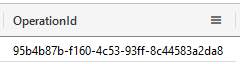
The query will return a OperationId and starts the export in the background. We can monitor the progress of the operation by executing:
.show operations <operation_ID>
The query will return valuable information about the operation. For now, column State is the most important one, because it indicates if the operation is InProgress, Completed or Failed.


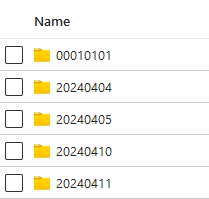
When the operation is completed, the export of all the data is finished. We can check this by opening the container of the external table.
And as expected, the container contains a folder of each date, as seen in the image below. The folder 00010101 is created because there were records in the table without a timestamp.

Each folder contains one or more parquet files:


Ingest data
Ok, now let’s ingest some data and check if the continuous export works:
.set-or-append MyTestTable <|
print id = int(1),
name = 'test',
value = 2.01,
timstamp = now()
First check in the table if the record is inserted:
MyTestTable | where id == 1
Yes it is:

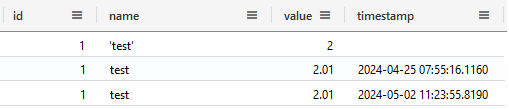
Now, let’s check it in the external table:
external_table("ExternalTable_MyTestTable")
| where id == 1
Yes, its also in the external table. It could take up to one minute before the ingested records are visible because of the interval of the continuous export.
At last, we check the last runtime of the continues export:
.show continuous-exports
And as you can see in the last column (of the screenshot below) it shows the datetime when the data is last exported.


Deleting data
By the way, the continuous export only supports ingestion of records. If a record will be deleted, this won’t effect the external table. Let me show you by deleting some records:
.delete table MyTestTable records <|
MyTestTable
| where id ==2
When checking the table:
MyTestTable | where id ==2
All records are deleted:

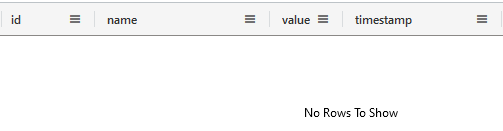
The external table still contains the records:
external_table("ExternalTable_MyTestTable")
| where id == 2
Result:


** UPDATE 21-05-2024 **
Also a purge will not delete the records in the external table
I also did not find a way to delete the records from the external table. So I guess the only way is to delete the blobs in the Storage Account.
Restore
In the previous chapter, we explained how to export the data to a Storage Account. Now we will use these files to restore the data. I restored the data in a different Azure Data Explorer cluster, but it can also be done in the same cluster.
There are several ways to import the data, I will use the Azure Data Explorer portal and LightIngest.
Portal
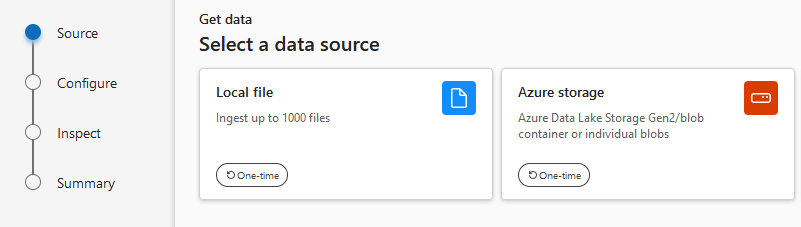
To import the data using the Azure Data Explorer portal, first open the portal and select “Get data”.

A wizard will open, which guide you through all the steps. In this case, we want to import from a Storage Account so we select “Azure storage”.

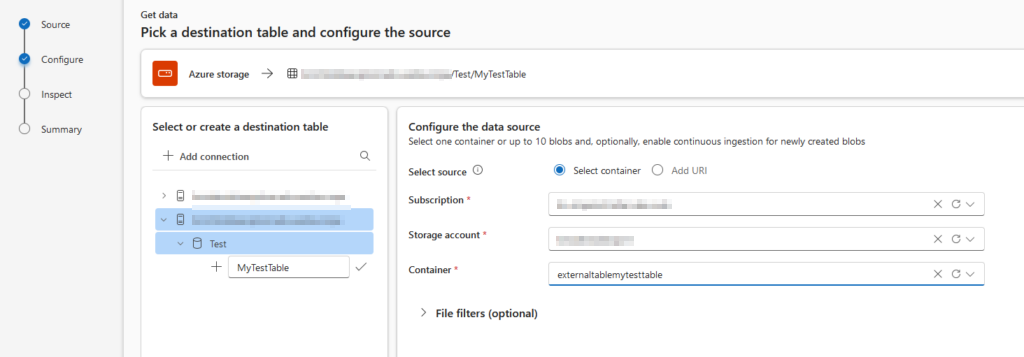
In the left pane, we select the destination table. It is also possible to create a new table, like in our example. In the right pane, we select the data source.

The next step, makes it possible to change the mapping, for example when a column has the wrong datatype. In our case, all the mappings are ok, so no need to change anything.


The last step will import all the blobs in the Storage Account into the destination table. The overview will show the progress of the imported blobs.

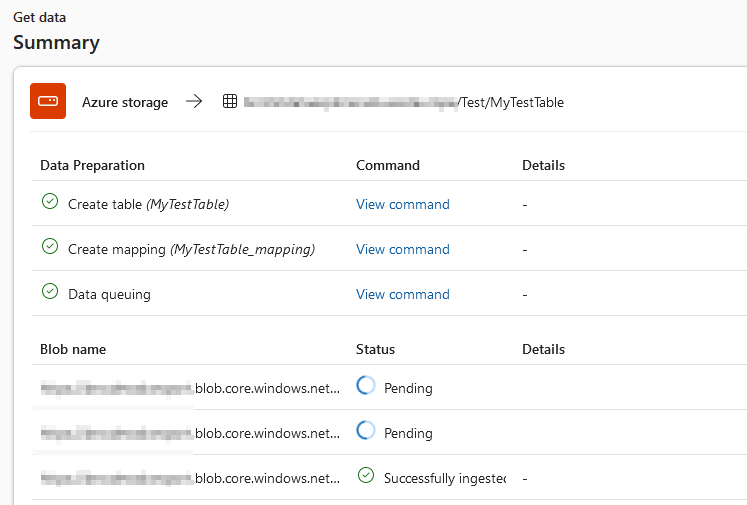
After a while, all the blobs will be successfully ingested.
LightIngest
There is also another way to import the data, using LightIngest. Some time ago, I already wrote a blog about this topic: Ingest historical data into Azure Data Explorer. But I will cover the main actions in this article as well.
The easiest way to generate a LightIngest command is by using the Azure Data Explorer portal. Open the query window:

And right-click on the database where you want to ingest the data, then select LightIngest:

Again, a wizard will start, which guide you through all the steps. We start by selecting the destination:

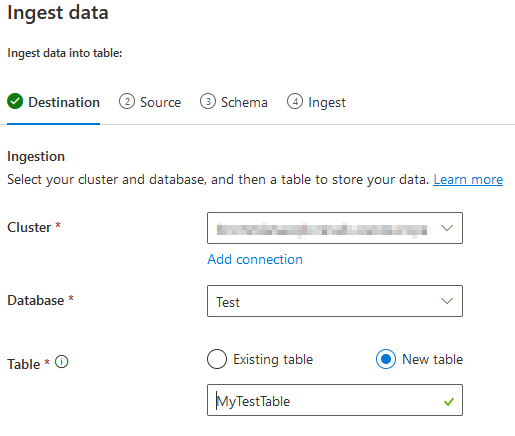
Next, we select the source:

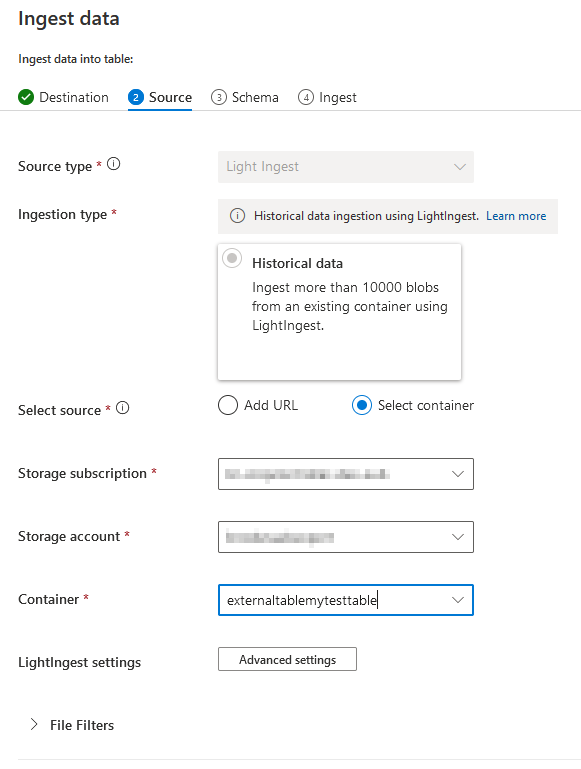
The next step, makes it possible to change the mapping, for example when a column has the wrong datatype. In our case, all the mappings are ok, so no need to change anything.

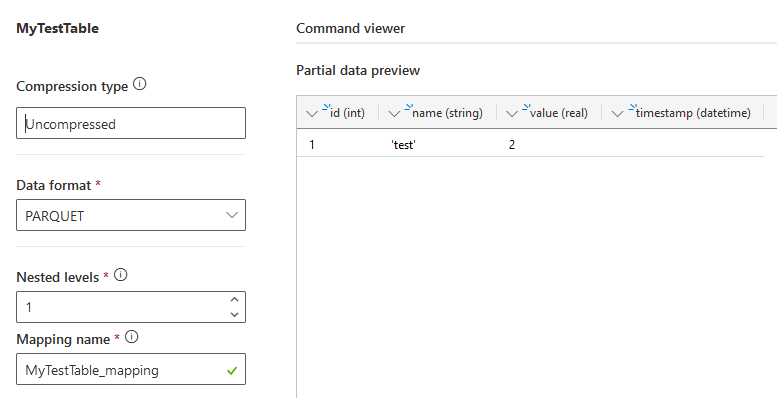
In the last step of the wizard, a command for LightIngest will be shown. Copy this command and execute it in a command prompt window.


The ingestion will automatically start and the progress of the ingestion is shown:

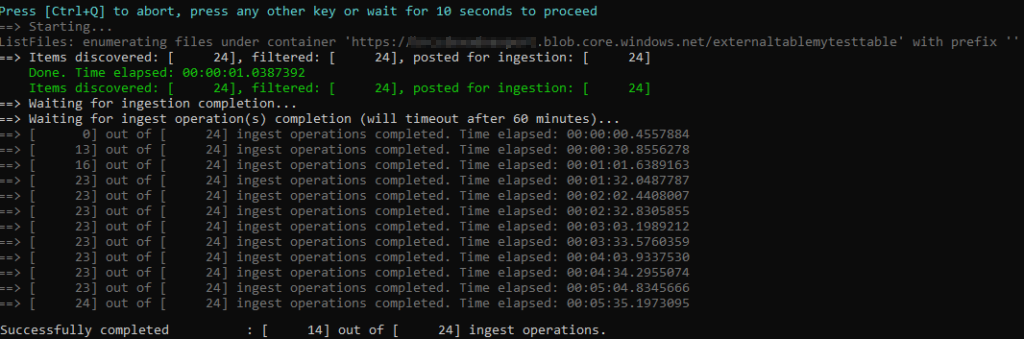
Now we have seen how to backup and how to restore. But this was only with a small dataset, does it also work with larger datasets?
Large datasets
To check how this functionality works with larger datasets, I created a table with around 150 million records with over 50 columns.
Backup
I have gone through the steps from this article and encountered an error when exporting the historical data:


The first part of the detailed error message:
Query execution lacks memory resources to complete (80DA0007): Partial query failure: Low memory condition (E_LOW_MEMORY_CONDITION). (message: bad allocation (E_LOW_MEMORY_CONDITION)). (0th of 2 in an AggregateException with message: One or more errors occurred. (Query execution lacks memory resources to complete (80DA0007): Partial query failure: Low memory condition (E_LOW_MEMORY_CONDITION). (message: bad allocation (E_LOW_MEMORY_CONDITION)).) (Query execution has resulted in error (0x80131500): Partial query failure: 0x80131500 (message: 'Failed in querying or exporting parquet files: hr: '2161770503' '0x80DA0007' ==> ExecutePluginOperator failure:
...
Well, I’m running a Dev(No SLA)_Standard_E2a_v4 cluster, so that might cause the problem. I solved it by splitting the export in several batches, simply by adding an extra where filter to the export script:
//export historical data
.export async to table ExternalTable_MyTestTable
<| MyTestTable
| where id between (100 .. 200)
| where cursor_before_or_at("<StartCursor>")
It works, but it took a lot more time to export all the data.
Restore
Next problem I encountered was with the data ingest using portal, because it is limited to 10.000 blobs. The portal does not give any message or error but just imports 10.000 blobs. I discovered this issue when checking the number of records in the table, this was significantly less than the source table.
Fortunately, LightIngest came to the rescue and ingested all the files without any problems. I forgot to measure the time it took by ingesting all the records using the portal, but I think LightIngest was faster as well.
Conclusion
Azure Data Explorer does not contain functionality to backup & restore databases as in the way we know it in SQL server. But in this article I have shown a good alternative by using continuous export to create a backup of the data and using LightIngest to ingest the data. There are still some things to keep in mind, like:
- Continuous export needs to be enabled per table
- Continuous export won’t process deleted records
- I encountered some problems when processing larger datasets
But in the end, by using continuous export and LightIngest, it is possible to backup and restore within Azure Data Explorer.